LLM终于学会推公式了!博世x清华推出FunctionEvolve:LLM-SRBench提升3.6倍,AI-Feynman满分
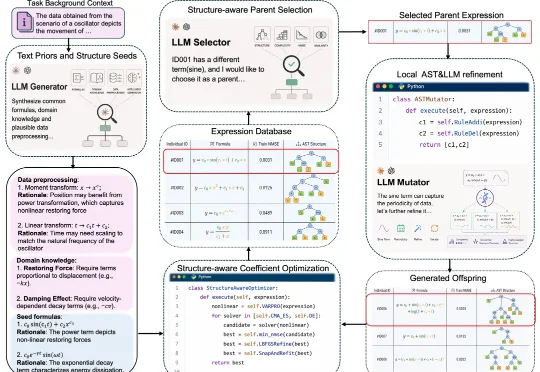
LLM终于学会推公式了!博世x清华推出FunctionEvolve:LLM-SRBench提升3.6倍,AI-Feynman满分来自博世中央研究院与清华大学的研究人员提出 FunctionEvolve 框架,在两大基准测试上大幅刷新了这项任务的结果。在 LLM-SRBench 的 129 个合成科学方程任务上,FunctionEvolve 最终给出的公式在 55.8% 的任务上与真实公式等价(SA@1 = 72/129),是此前最好结果的 3.6 倍;
来自主题: AI技术研报
7521 点击 2026-06-20 10:24